C# Regular Expressions Tutorial with Examples
1. Regular expression
A regular expression defines a search pattern for strings. Regular expressions can be used to search, edit and manipulate text. The pattern defined by the regular expression may match one or several times or not at all for a given string.
The abbreviation for regular expression is regex.
The abbreviation for regular expression is regex.
Regular expressions are supported by most programming languages, e.g., C#, Java, Perl, Groovy, etc. Unfortunately each language supports regular expressions slightly different.
You may be interested:
2. Rule writing regular expressions
No | Regular Expression | Description |
1 | . | Matches one or more characters. |
2 | ^regex | Finds regex that must match at the beginning of the line. |
3 | regex$ | Finds regex that must match at the end of the line. |
4 | [abc] | Set definition, can match the letter a or b or c. |
5 | [abc][vz] | Set definition, can match a or b or c followed by either v or z. |
6 | [^abc] | When a caret appears as the first character inside square brackets, it negates the pattern. This can match any character except a or b or c. |
7 | [a-d1-7] | Ranges: matches a letter between a and d and figures from 1 to 7. |
8 | X|Z | Finds X or Z. |
9 | XZ | Finds X directly followed by Z. |
10 | $ | Checks if a line end follows. |
11 | \d | Any digit, short for [0-9] |
12 | \D | A non-digit, short for [^0-9] |
13 | \s | A whitespace character, short for [ \t\n\x0b\r\f] |
14 | \S | A non-whitespace character, short for [^\s] |
15 | \w | A word character, short for [a-zA-Z_0-9] |
16 | \W | A non-word character [^\w] |
17 | \S+ | Several non-whitespace characters |
18 | \b | Matches a word boundary where a word character is [a-zA-Z0-9_]. |
19 | * | Occurs zero or more times, is short for {0,} |
20 | + | Occurs one or more times, is short for {1,} |
21 | ? | Occurs no or one times, ? is short for {0,1}. |
22 | {X} | Occurs X number of times, {} describes the order of the preceding liberal |
23 | {X,Y} | Occurs between X and Y times, |
24 | *? | ? after a quantifier makes it a reluctant quantifier. It tries to find the smallest match. |
3. Special characters in C# Regex
Special characters in C# Regex:
\.[{(*+?^$|The characters listed above are special characters. In C# Regex you want it understood that character in the normal way you should add a \ in front.
Example dot character . C# Regex is interpreted as one or more characters, if you want it interpreted as a dot character normally required mark \ ahead.
Example dot character . C# Regex is interpreted as one or more characters, if you want it interpreted as a dot character normally required mark \ ahead.
// Regex pattern describe one or more characters.
string regex = ".";
// Regex pattern describe a dot character.
string regex = "\\.";
string regex = @"\.";4. Using Regex.IsMatch(string)
- Regex class
...
// Check the entire String object matches the regex or not.
public bool IsMatch(string regex)
..Using the method Regex.IsMatch(string regex) allows you to check the entire string matches the regex or not. This is the most common way. Consider these examples:
Regex .
In the regular expression of C#, the dot character (.) Is a special character. It represents one or more characters. If you want C# to understand it is a dot in the usual sense you need to write "\\." Or @ "\."
DotExample.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
namespace RegularExpressionTutorial
{
class DotExample
{
public static void Main(string[] args)
{
// String with 0 character (Empty string).
string s1 = "";
Console.WriteLine("s1=" + s1);
// Check s1
// Match one or more characters.
// Rule .
// ==> False
bool match = Regex.IsMatch(s1, ".");
Console.WriteLine(" -Match . " + match);
// String with 1 character.
string s2 = "a";
Console.WriteLine("s2=" + s2);
// Check s2
// Match one or more characters
// Rule .
// ==> True
match = Regex.IsMatch(s2, ".");
Console.WriteLine(" -Match . " + match);
// String with 3 characters.
string s3 = "abc";
Console.WriteLine("s3=" + s3);
// Check s3
// Match one or more characters.
// Rule .
// ==> true
match = Regex.IsMatch(s3, ".");
Console.WriteLine(" -Match . " + match);
// String with 3 characters.
string s4 = "abc";
Console.WriteLine("s4=" + s4);
// Check s4
// Match with dot charactor.
// ==> False
match = Regex.IsMatch(s4, @"\.");
Console.WriteLine(" -Match \\. " + match);
// String with 1 character (Dot character).
string s5 = ".";
Console.WriteLine("s5=" + s5);
// Check s5
// Match with dot charactor
// ==> True
match = Regex.IsMatch(s5, @"\.");
Console.WriteLine(" -Match \\. " + match);
Console.Read();
}
}
}Run the example:
s1=
-Match . False
s2=a
-Match . True
s3=abc
-Match . True
s4=abc
-Match \. False
s5=.
-Match \. TrueAnother example uses Regex.IsMath (string):
RegexIsMatchExample.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
namespace RegularExpressionTutorial
{
class RegexIsMatchExample
{
public static void Main(string[] args)
{
// String with one character
string s2 = "m";
Console.WriteLine("s2=" + s2);
// Check s2
// Start by 'm'
// Rule ^
// ==> true
bool match = Regex.IsMatch(s2, "^m");
Console.WriteLine(" -Match ^m " + match);
// A string with 7 characters
string s3 = "MMnnnnn";
Console.WriteLine("s3=" + s3);
// Check the entire s3
// Start by MM
// Rule ^
// ==> true
match = Regex.IsMatch(s3, "^MM");
Console.WriteLine(" -Match ^MM " + match);
// Check s3
// Start by MM
// Next character 'n', appearing one or more times.
// Rule ^ and +
// ==> true
match = Regex.IsMatch(s3, "^MMn+");
Console.WriteLine(" -Match ^MMn+ " + match);
// String with one character
String s4 = "p";
Console.WriteLine("s4=" + s4);
// Check s4 ending with 'p'
// Rule $
// ==> true
match = Regex.IsMatch(s4, "p$");
Console.WriteLine(" -Match p$ " + match);
// A string with 6 characters.
string s5 = "122nnp";
Console.WriteLine("s5=" + s5);
// Check the entire s5 end withs 'p'
// ==> true
match = Regex.IsMatch(s5, "p$");
Console.WriteLine(" -Match p$ " + match);
// Check the entire s5
// Start with one or more characters (Rule . )
// Followed by 'n', appear one or up to three times (Rule n{1,3} )
// End withs 'p' (Rule: p$)
// Combine the rules: . , {x, y}, $
// ==> true
match = Regex.IsMatch(s5, ".n{1,3}p$");
Console.WriteLine(" -Match .n{1,3}p$ " + match);
String s6 = "2ybcd";
Console.WriteLine("s6=" + s6);
// Check s6
// Start by '2'
// Next 'x' or 'y' or 'z' (Rule [xyz])
// Followed by any, appear 0 or more times.
// Combine the rules: [xyz] , *
// ==> true
match = Regex.IsMatch(s6, "2[xyz].*");
Console.WriteLine(" -Match 2[xyz].* " + match);
string s7 = "2bkbv";
Console.WriteLine("s7=" + s7);
// Check s7 Start any, one or more times
// Followed by 'a' or 'b', or 'c': [abc]
// Next 'z' or 'v': [zv]
// Followed by any (0 or more times)
// ==> true
match = Regex.IsMatch(s7, ".[abc][zv].*");
Console.WriteLine(" -Match .[abc][zv].* " + match);
Console.Read();
}
}
}Results of running the example:
s2=m
-Match ^m True
s3=MMnnnnn
-Match ^MM True
-Match ^MMn+ True
s4=p
-Match p$ True
s5=122nnp
-Match p$ True
-Match .n{1,3}p$ True
s6=2ybcd
-Match 2[xyz].* True
s7=2bkbv
-Match .[abc][zv].* TrueNext example:
RegexIsMatchExample2.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
namespace RegularExpressionTutorial
{
class RegexIsMatchExample2
{
public static void Main(string[] args)
{
String s = "The film Tom and Jerry!";
// Check entire s
// Begin by any characters appear 0 or more times (Rule: .*)
// Next "Tom" or "Jerry"
// End with any characters appear 1 or more times (Rule: .)
// Combine the rules: ., *, X|Z
bool match = Regex.IsMatch(s, ".*(Tom|Jerry).");
Console.WriteLine("s=" + s);
Console.WriteLine("-Match .*(Tom|Jerry). " + match);
s = "The cat";
// ==> false
match = Regex.IsMatch(s, ".*(Tom|Jerry).");
Console.WriteLine("s=" + s);
Console.WriteLine("-Match .*(Tom|Jerry). " + match);
s = "The Tom cat";
// ==> true
match = Regex.IsMatch(s, ".*(Tom|Jerry).");
Console.WriteLine("s=" + s);
Console.WriteLine("-Match .*(Tom|Jerry). " + match);
Console.Read();
}
}
}Results of running the example:
s=The film Tom and Jerry!
-Match .*(Tom|Jerry). True
s=The cat
-Match .*(Tom|Jerry). False
s=The Tom cat
-Match .*(Tom|Jerry). True5. Using Regex.Split & Regex.Replace
One of the other useful methods is Regex.Split (string, string), which separates a string into substrings. For example, you have the string "One, Two, Three" and you want to split it into 3 substrings, separated by commas.
SplitWithRegexExample.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
namespace RegularExpressionTutorial
{
class SplitWithRegexExample
{
public static void Main(string[] args)
{
// \t: TAB character
// \n: NewLine character
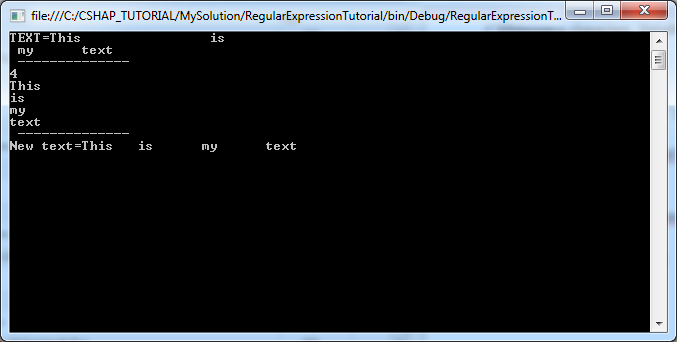
string TEXT = "This \t\t is \n my \t text";
Console.WriteLine("TEXT=" + TEXT);
// Define a regex:
// Whitespace appear 1 or more times.
// Whitespace characters: \t\n\x0b\r\f
// Rulers: \s and +
String regex = @"\s+";
Console.WriteLine(" -------------- ");
String[] splitString = Regex.Split(TEXT, regex);
Console.WriteLine(splitString.Length); // ==> 4
foreach (string str in splitString)
{
Console.WriteLine(str);
}
Console.WriteLine(" -------------- ");
// Replace whitespaces with TAB
String newText = Regex.Replace(TEXT, "\\s+", "\t");
Console.WriteLine("New text=" + newText);
Console.Read();
}
}
}Run the example:
6. Sử dụng MatchCollection & Match
Use Regex.Matches(...) method to search all the substrings of a string, matching a regular expression, this method returns a MatchCollection object.
** Regex.Matches() **
public MatchCollection Matches(
string input
)
public MatchCollection Matches(
string input,
int startat
)
public static MatchCollection Matches(
string input,
string pattern
)
public static MatchCollection Matches(
string input,
string pattern,
RegexOptions options,
TimeSpan matchTimeout
)
public static MatchCollection Matches(
string input,
string pattern,
RegexOptions options
)The following example, splits a string into substrings, separated by whitespace.
MatchCollectionExample.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
namespace RegularExpressionTutorial
{
class MatchCollectionExample
{
public static void Main(string[] args)
{
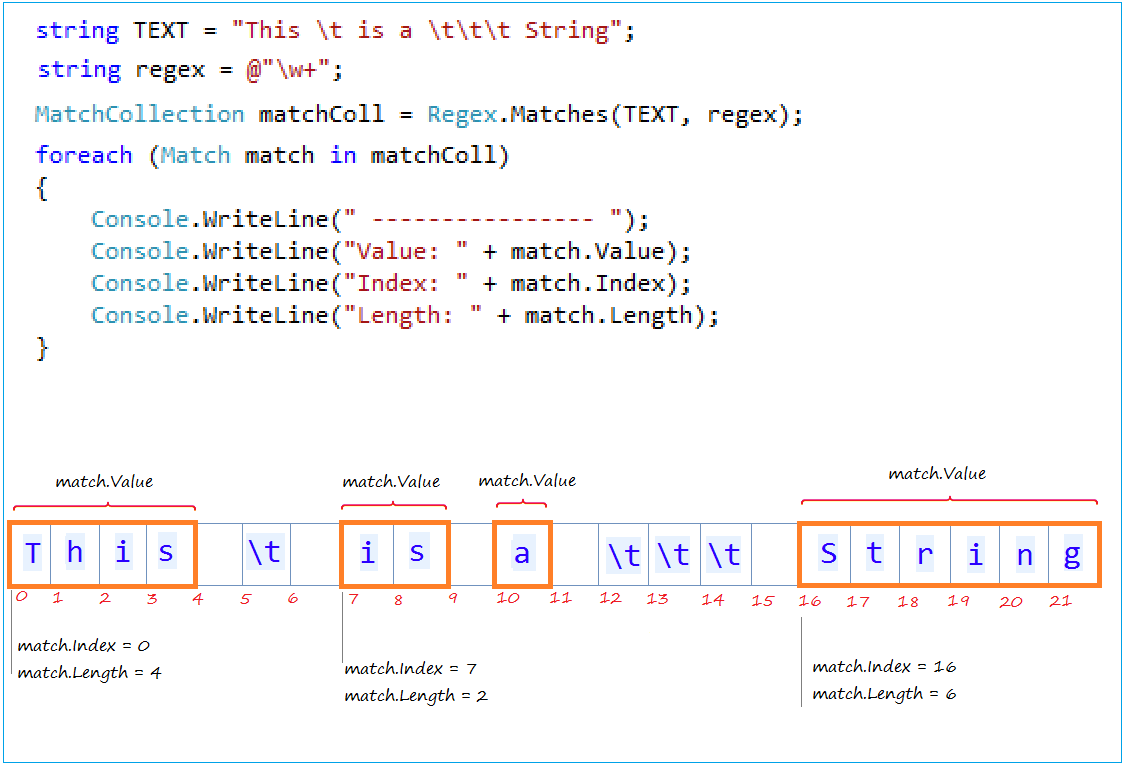
string TEXT = "This \t is a \t\t\t String";
// \w : A word character, short for [a-zA-Z_0-9]
// \w+ : Word character, appear one or more times.
string regex = @"\w+";
MatchCollection matchColl = Regex.Matches(TEXT, regex);
foreach (Match match in matchColl)
{
Console.WriteLine(" ---------------- ");
Console.WriteLine("Value: " + match.Value);
Console.WriteLine("Index: " + match.Index);
Console.WriteLine("Length: " + match.Length);
}
Console.Read();
}
}
}Result of running example:
----------------
Value: This
Index: 0
Length: 4
----------------
Value: is
Index: 7
Length: 2
----------------
Value: a
Index: 10
Length: 1
----------------
Value: String
Index: 16
Length: 67. Group
A regular expression you can split into groups:
// A regular expression
string regex = @"\s+=\d+";
// Writing as three group, by marking ( )
string regex2 = @"(\s+)(=)(\d+)";
// Two group
string regex3 = @"(\s+)(=\d+)";
The group can be nested, and so need a rule indexing the group. The entire pattern is defined as the group 0. The remaining group described similar illustration below:

Note: Use (?:Pattern) to inform C# does not see this as a group (None-capturing group)
You can define a named capturing group (?<groupName>pattern) or (?'groupName'pattern), and you can access the content matched with match.Groups["groupName"]. The regex is longer, but the code is more meaningful, since it indicates what you are trying to match or extract with the regex.
Named capturing group can also be access via match.Groups[groupIndex] with the same numbering scheme.
Named capturing group can also be access via match.Groups[groupIndex] with the same numbering scheme.
-
Let's look at an example using the named group:
NamedGroupExample.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
namespace RegularExpressionTutorial
{
class NamedGroupExample
{
public static void Main(string[] args)
{
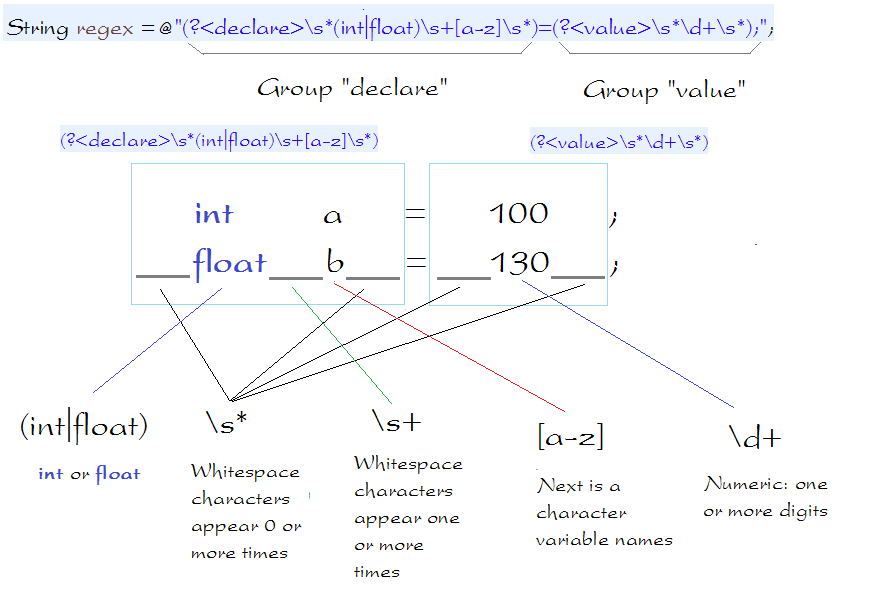
string TEXT = " int a = 100; float b= 130; float c= 110 ; ";
// Use (?<groupName>pattern) to define a group named: groupName
// Defined group named 'declare': using (?<declare>...)
// And a group named 'value': use: (?<value>..)
string regex = @"(?<declare>\s*(int|float)\s+[a-z]\s*)=(?<value>\s*\d+\s*);";
MatchCollection matchCollection = Regex.Matches(TEXT, regex);
foreach (Match match in matchCollection)
{
string group = match.Groups["declare"].Value;
Console.WriteLine("Full Text: " + match.Value);
Console.WriteLine("<declare>: " + match.Groups["declare"].Value);
Console.WriteLine("<value>: " + match.Groups["value"].Value);
Console.WriteLine("------------------------------");
}
Console.Read();
}
}
}Results of running the example:
Full Text: int a = 100;
<declare>: int a
<value>: 100
------------------------------
Full Text: float b = 130;
<declare>: float b
<value>: 130
------------------------------
Full Text: float c = 110 ;
<declare>: float c
<value>: 110
------------------------------Just to clarify you can see the illustration below:
8. Using MatchCollection, Group and *?
In some situations *? very important, take a look at the following example:
// This is a regex
// any characters, appear 0 or more times,
// followed by ' and >
string regex = ".*'>";
// TEXT1 match the regex above.
string TEXT1 = "FILE1'>";
// And TEXT2 match the regex above.
string TEXT2 = "FILE1'> <a href='http://HOST/file/FILE2'>";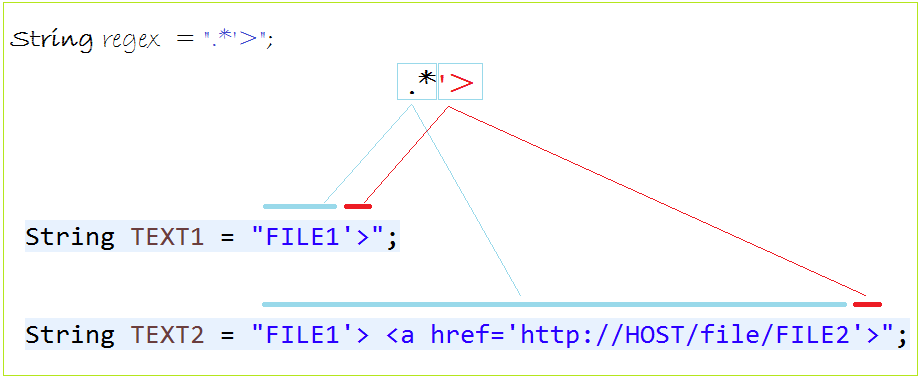
*? will find the smallest match. We consider the following example:
NamedGroupExample2.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
namespace RegularExpressionTutorial
{
class NamedGroupExample2
{
public static void Main(string[] args)
{
string TEXT = "<a href='http://HOST/file/FILE1'>File 1</a>"
+ "<a href='http://HOST/file/FILE2'>File 2</a>";
// Define group named fileName.
// * means appear 0 or more times.
// *? means a smallest match.
string regex = "/file/(?<fileName>.*?)'>";
MatchCollection matchCollection = Regex.Matches(TEXT, regex);
foreach (Match match in matchCollection)
{
Console.WriteLine("File Name = " + match.Groups["fileName"].Value);
Console.WriteLine("------------------------------");
}
Console.Read();
}
}
}Results of running the example:
File Name = FILE1
------------------------------
File Name = FILE2
------------------------------C# Programming Tutorials
- Inheritance and polymorphism in C#
- What is needed to get started with C#?
- Quick learning C# for Beginners
- Install Visual Studio 2013 on Windows
- Abstract class and Interface in C#
- Install Visual Studio 2015 on Windows
- Compression and decompression in C#
- C# Multithreading Programming Tutorial with Examples
- C# Delegates and Events Tutorial with Examples
- Install AnkhSVN on Windows
- C# Programming for Team using Visual Studio and SVN
- Install .Net Framework
- Access Modifier in C#
- C# String and StringBuilder Tutorial with Examples
- C# Properties Tutorial with Examples
- C# Enums Tutorial with Examples
- C# Structures Tutorial with Examples
- C# Generics Tutorial with Examples
- C# Exception Handling Tutorial with Examples
- C# Date Time Tutorial with Examples
- Manipulating files and directories in C#
- C# Streams tutorial - binary streams in C#
- C# Regular Expressions Tutorial with Examples
- Connect to SQL Server Database in C#
- Work with SQL Server database in C#
- Connect to MySQL database in C#
- Work with MySQL database in C#
- Connect to Oracle Database in C# without Oracle Client
- Work with Oracle database in C#
Show More