Jsoup Java Html Parser Tutorial with Examples
1. What is Jsoup?
Jsoup is a java html parser. It is a java library that is used to parse HTML document. Jsoup provides api to extract and manipulate data from URL or HTML file. It uses DOM, CSS and Jquery-like methods for extracting and manipulating file.

Let's look at an example with Jsoup:
HelloJsoup.java
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class HelloJsoup {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}2. Jsoup Library
You can use Maven or download the Jsoup library.
Using maven:
<!-- http://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>Or download:
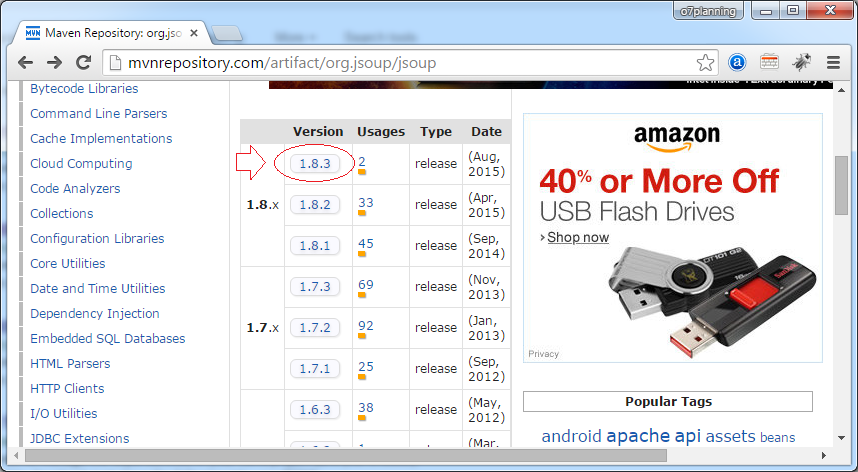
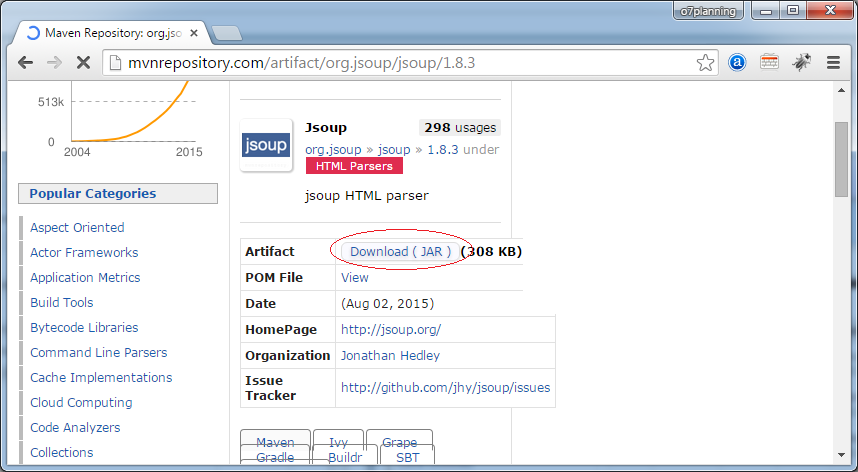
3. Jsoup API
Jsoup includes many classes, however, its three most important classes are:
- org.jsoup.Jsoup
- org.jsoup.nodes.Document
- org.jsoup.nodes.Element
- Jsoup.java
Method | Description |
static Connection connect(String url) | create and returns connection of URL. |
static Document parse(File in, String charsetName) | parses the specified charset file into document. |
static Document parse(File in, String charsetName, String baseUri) | parses the specified charset and baseUri file into Document. |
static Document parse(String html) | parses the given html code into document. |
static Document parse(String html, String baseUri) | parses the given html code with baseUri into Document. |
static Document parse(URL url, int timeoutMillis) | parses the given URL into Document. |
static String clean(String bodyHtml, Whitelist whitelist) | returns safe HTML from input HTML, by parsing input HTML and filtering it through a white-list of permitted tags and attributes. |
- Document.java
Methods | Description |
Element body() |
Accessor to the document's body element.
|
Charset charset() |
Returns the charset used in this document.
|
void charset(Charset charset) |
Sets the charset used in this document.
|
Document clone() |
Create a stand-alone, deep copy of this node, and all of its children.
|
Element createElement(String tagName) |
Create a new Element, with this document's base uri.
|
static Document createShell(String baseUri) |
Create a valid, empty shell of a document, suitable for adding more elements to.
|
Element head() |
Accessor to the document's head element.
|
String location() |
Get the URL this Document was parsed from.
|
String nodeName() |
Get the node name of this node.
|
Document normalise() |
Normalise the document.
|
String outerHtml() |
Get the outer HTML of this node.
|
Document.OutputSettings outputSettings() |
Get the document's current output settings.
|
Document outputSettings(Document.OutputSettings outputSettings) |
Set the document's output settings.
|
Document.QuirksMode quirksMode() | |
Document quirksMode(Document.QuirksMode quirksMode) | |
Element text(String text) |
Set the text of the body of this document.
|
String title() |
Get the string contents of the document's title element.
|
void title(String title) |
Set the document's title element.
|
boolean updateMetaCharsetElement() |
Returns whether the element with charset information in this document is updated on changes through Document.charset(Charset) or not.
|
void updateMetaCharsetElement(boolean update) |
Sets whether the element with charset information in this document is updated on changes through Document.charset(Charset) or not.
|
- Element.java
4. Manipulating Document
Create Documet from URL
GetDocumentFromURL.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromURL {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}Running example:
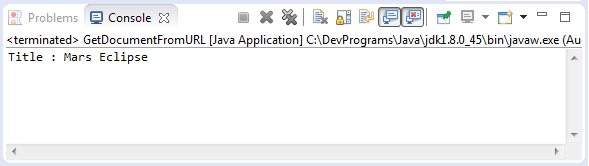
Create Document from File
GetDocumentFromFile.java
package org.o7planning.tutorial.jsoup.document;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromFile {
public static void main(String[] args) throws IOException {
File htmlFile = new File("C:/index.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
String title = doc.title();
System.out.println("Title : " + title);
}
}Create Document from String
GetDocumentFromString.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromString {
public static void main(String[] args) throws IOException {
String htmlString = "<html><head><title>Simple Page</title></head>"
+ "<body>Hello</body></html>";
Document doc = Jsoup.parse(htmlString);
String title = doc.title();
System.out.println("Title : " + title);
System.out.println("Content:\n");
System.out.println(doc.toString());
}
}Running example:
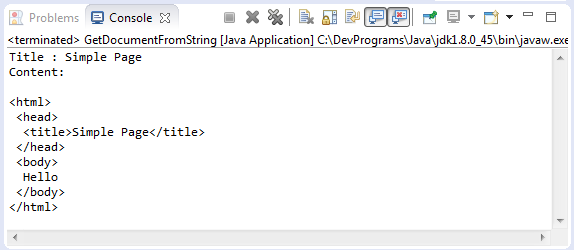
Parsing HTML Fragment
A full HTML document includes Header and Body, sometimes you also need to parse an HTML fragment. And you can get a full HTML document includes headers and body. See for example:
ParsingBodyFragment.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParsingBodyFragment {
public static void main(String[] args) throws IOException {
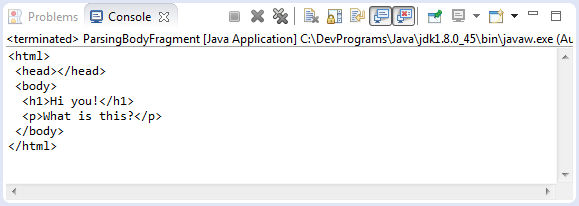
String htmlFragment = "<h1>Hi you!</h1><p>What is this?</p>";
Document doc = Jsoup.parseBodyFragment(htmlFragment);
String fullHtml = doc.html();
System.out.println(fullHtml);
}
}Running example:
5. DOM Methods
Jsoup has some methods similar to the method in the DOM model ( Parsing XML document)
Methods | Description |
Element getElementById(String id) | Find an element by ID, including or under this element. |
Elements getElementsByTag(String tag) | Finds elements, including and recursively under this element, with the specified tag name. |
Elements getElementsByClass(String className) | Find elements that have this class, including or under this element. |
Elements getElementsByAttribute(String key) | Find elements that have a named attribute set. Case insensitive. |
Elements siblingElements() | Get sibling elements. |
Element firstElementSibling() | Gets the first element sibling of this element. |
Element lastElementSibling() | Gets the last element sibling of this element. |
...... | |
The method of retrieving data of Element.
Method | Description |
String attr(String key) | Get an attribute's value by its key. |
void attr(String key, String value) | Set an attribute. If the attribute already exists, it is replaced. |
String id() | Return The id attribute, if present, or an empty string if not. |
String className() | Gets the literal value of this element's "class" attribute, which may include multiple class names, space separated. (E.g. on <div class="header gray"> returns, " header gray") |
Set<String> classNames() | Get all of the element's class names. E.g. on element <div class="header gray">, returns a set of two elements "header", "gray". Note that modifications to this set are not pushed to the backing class attribute; use the classNames(java.util.Set) method to persist them. |
String text() | Gets the combined text of this element and all its children. |
void text(String value) | Set the text of this element. |
String html() | Retrieves the element's inner HTML. E.g. on a <div><p>a</p></div>, would return <p>a</p>. (Whereas Node.outerHtml() would return <div><p>a</p></div>.) |
void html(String value) | Set this element's inner HTML. Clears the existing HTML first. |
Tag tag() | Get the Tag for this element |
String tagName() | Get the name of the tag for this element. E.g. div |
...... | |
The methods to manipulate HTML:
Methods | Description |
Element append(String html) | Add inner HTML to this element. The supplied HTML will be parsed, and each node appended to the end of the children. |
Element prepend(String html) | Add inner HTML into this element. The supplied HTML will be parsed, and each node prepended to the start of the element's children. |
Element appendText(String text) | Create and append a new TextNode to this element. |
Element prependText(String text) | Create and prepend a new TextNode to this element. |
Element appendElement(String tagName) | Create a new element by tag name, and add it as the last child. |
Element prependElement(String tagName) | Create a new element by tag name, and add it as the first child. |
Element html(String value) | Set this element's inner HTML. Clears the existing HTML first. |
...... | |
For example, using the DOM methods, parsing an HTML document and retrieve information of form tag.
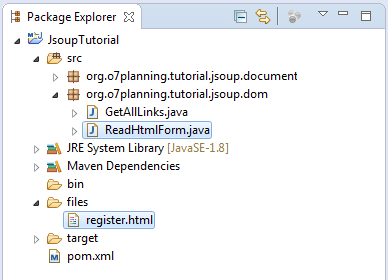
register.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Register</title>
</head>
<body>
<form id="registerForm" action="doRegister" method="post">
<table>
<tr>
<td>User Name</td>
<td><input type="text" name="userName" value="Tom" /></td>
</tr>
<tr>
<td>Password</td>
<td><input type="password" name="password" value="Tom001" /></td>
</tr>
<tr>
<td>Email</td>
<td><input type="email" name="email" value="theEmail@gmail.com" /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" name="submit" value="Submit" /></td>
</tr>
</table>
</form>
</body>
</html>ReadHtmlForm.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
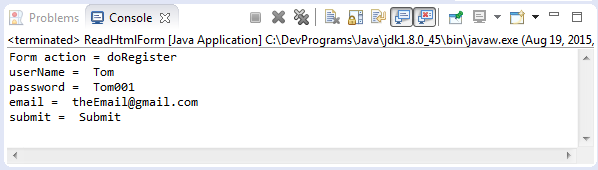
public class ReadHtmlForm {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.parse(new File("files/register.html"), "utf-8");
Element form = doc.getElementById("registerForm");
System.out.println("Form action = "+ form.attr("action"));
Elements inputElements = form.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println(key + " = " + value);
}
}
}Running example:
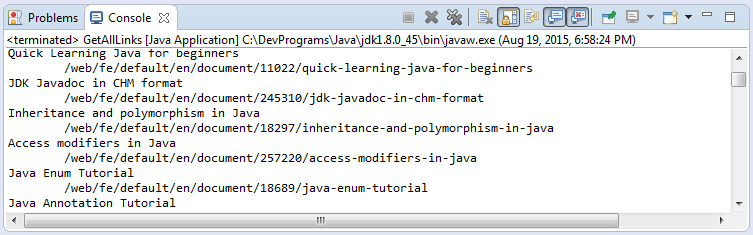
GetAllLinks.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class GetAllLinks {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://o7planning.org").get();
// Elements extends ArrayList<Element>.
Elements aElements = doc.getElementsByTag("a");
for (Element aElement : aElements) {
String href = aElement.attr("href");
String text = aElement.text();
System.out.println(text);
System.out.println("\t" + href);
}
}
}Running example:
6. The methods similar to jQuery,Css
You want to find or manipulate elements using a CSS or jquery-like selector syntax?
JSoup give you a few methods to do this:
- Element.select(String selector)
- Elements.select(String selector)
Example:
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// a with href
Elements links = doc.select("a[href]");
// img with src ending .png
Elements pngs = doc.select("img[src$=.png]");
// div with class=masthead
Element masthead = doc.select("div.masthead").first();
// direct a after h3
Elements resultLinks = doc.select("h3.r > a");Jsoup elements support a CSS (or jquery) like selector syntax to find matching elements, that allows very powerful and robust queries.
The select method is available in a Document, Element, or in Elements. It is contextual, so you can filter by selecting from a specific element, or by chaining select calls.
Select returns a list of Elements (as Elements), which provides a range of methods to extract and manipulate the results.
The select method is available in a Document, Element, or in Elements. It is contextual, so you can filter by selecting from a specific element, or by chaining select calls.
Select returns a list of Elements (as Elements), which provides a range of methods to extract and manipulate the results.
Selector overview
Selector | Description |
tagname | find elements by tag, e.g. a |
ns|tag | find elements by tag in a namespace, e.g. fb|name finds <fb:name> elements |
#id | find elements by ID, e.g. #logo |
.class: | find elements by class name, e.g. .masthead |
[attribute] | elements with attribute, e.g. [href] |
[^attr] | elements with an attribute name prefix, e.g. [^data-] finds elements with HTML5 dataset attributes |
[attr=value] | elements with attribute value, e.g. [width=500] (also quotable, like sequence") |
[attr^=value], [attr$=value], [attr*=value] | elements with attributes that start with, end with, or contain the value, e.g. [href*=/path/] |
[attr~=regex] | elements with attribute values that match the regular expression; e.g. img[src~=(?i)\.(png|jpe?g)] |
* | all elements, e.g. * |
Selector combinations
Selector | Description |
el#id | elements with ID, e.g. div#logo |
el.class | elements with class, e.g. div.masthead |
el[attr] | elements with attribute, e.g. a[href] |
Any combination, e.g. a[href].highlight | |
ancestor child | child elements that descend from ancestor, e.g. .body p finds p elements anywhere under a block with class "body" |
parent > child | child elements that descend directly from parent, e.g. div.content > p finds p elements; and body > * finds the direct children of the body tag |
siblingA + siblingB | finds sibling B element immediately preceded by sibling A, e.g. div.head + div |
siblingA ~ siblingX | finds sibling X element preceded by sibling A, e.g. h1 ~ p |
el, el, el | group multiple selectors, find elements that match any of the selectors; e.g. div.masthead, div.logo |
Pseudo selectors
Selector | Description |
:lt(n) | find elements whose sibling index (i.e. its position in the DOM tree relative to its parent) is less than n; e.g. td:lt(3) |
:gt(n) | find elements whose sibling index is greater than n; e.g. div p:gt(2) |
:eq(n) | find elements whose sibling index is equal to n; e.g. form input:eq(1) |
:has(seletor) | find elements that contain elements matching the selector; e.g. div:has(p) |
:not(selector) | find elements that do not match the selector; e.g. div:not(.logo) |
:contains(text) | find elements that contain the given text. The search is case-insensitive; e.g. p:contains(jsoup) |
:containsOwn(text) | find elements that directly contain the given text |
:matches(regex) | find elements whose text matches the specified regular expression; e.g. div:matches((?i)login) |
:matchesOwn(regex) | find elements whose own text matches the specified regular expression |
Note that the above indexed pseudo-selectors are 0-based, that is, the first element is at index 0, the second at 1, et | |
QueryLinks.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class QueryLinks {
public static void main(String[] args) throws IOException {
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// Query <a> elements, href contain /document/
String cssQuery = "a[href*=/document/]";
Elements elements= doc.select(cssQuery);
Iterator<Element> iterator = elements.iterator();
while(iterator.hasNext()) {
Element e = iterator.next();
System.out.println(e.attr("href"));
}
}
}Results:
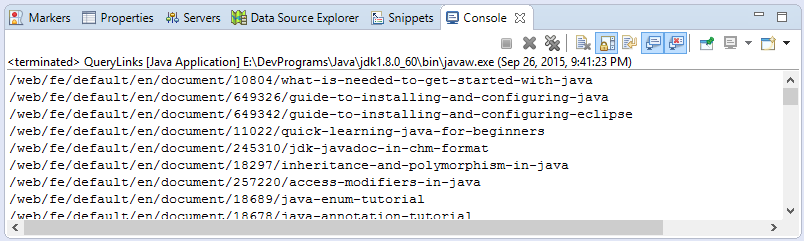
document.html
<html>
<head>
<title>Jsoup Example</title>
</head>
<body>
<h1>Java Tutorial For Beginners</h1>
<br>
<div id="content">
Content ....
</div>
<div class="related-container">
<h3>Related Documents</h3>
<a href="http://o7planning.org/web/fe/default/en/document/649342/guide-to-installing-and-configuring-eclipse">
Guide to Installing and Configuring Eclipse
</a>
<a href="http://o7planning.org/web/fe/default/en/document/649326/guide-to-installing-and-configuring-java">
Guide to Installing and Configuring Java
</a>
<a href="http://o7planning.org/web/fe/default/en/document/245310/jdk-javadoc-in-chm-format">
Jdk Javadoc in chm format
</a>
</div>
</body>
</html>SelectorDemo1.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SelectorDemo1 {
public static void main(String[] args) throws IOException {
File htmlFile = new File("document.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
// First <div> element has class ="related-container"
Element div = doc.select("div.related-container").first();
// List the <h3>, the direct child elements of the current element.
Elements h3Elements = div.select("> h3");
// Get first <h3> element
Element h3 = h3Elements.first();
System.out.println(h3.text());
// List <a> elements, is a descendant of the current element
Elements aElements = div.select("a");
// Query the current element list.
// The element that href contains 'installing'.
Elements aEclipses = aElements.select("[href*=Installing]");
Iterator<Element> iterator = aEclipses.iterator();
while (iterator.hasNext()) {
Element a = iterator.next();
System.out.println("Document: "+ a.text());
}
}
}Results:
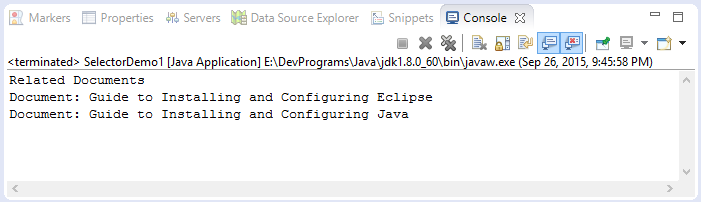
Java Open Source Libraries
- Java JSON Processing API Tutorial (JSONP)
- Using Scribe OAuth Java API with Google OAuth2
- Get Hardware information in Java application
- Restfb Java API for Facebook
- Create Credentials for Google Drive API
- Java JDOM2 Tutorial with Examples
- Java XStream Tutorial with Examples
- Jsoup Java Html Parser Tutorial with Examples
- Retrieve Geographic information based on IP Address using GeoIP2 Java API
- Read and Write Excel file in Java using Apache POI
- Explore the Facebook Graph API
- Java Sejda WebP ImageIO convert Images to WEBP
- Java JAVE Convert audio and video to mp3
- Manipulating files and folders on Google Drive using Java
Show More